En este documento, vamos a utilizar varios ejercicios para familiarizarnos con la gestión de datos en R. Les aconsejo:
- Crear una carpeta única para poner todo el contenido del curso
- descargar la carpeta de datos del curso, y ponerla como sub-carpeta “Datos”
- Crear una subcarpeta “scripts_R” donde poner todos los codigos R que van a escribir en los proximos días:
- Pensar en la organización de esos codigos (1 archivo por sesión, o un archivo por ejercicio)
- Poner nombres de archivos que les permita volver a mirarlo, en 1 mes, o 10 años, si necesitan hacer un tratamiento parecido a lo que hicieron en un ejercicio
- Crear una subcarpeta diferente “Resultados” para guardar archivos creados desde sus codigos en R, figuras, o datos
fol_Datos <- "../Datos/"
fol_Results <- "../Resultados/"1 Utilizar filtros simples
1.1 Ejercicio
- Crear una matriz de abundancia con únicamente los sitios de referencia de las hydro-eco-región de primer nivel: 2, 6 y 7 (Sur-Este de Francia)
- la matriz no puede tener especies que no están presentes en esos sitios
- ordenar las columnas por orden alfabético de los códigos de especies
- Comparar la riqueza de las especies en los 5% de los sitios de agua más acida y lo 5% de los sitios de agua más alcalina de esa nueva matriz
1.2 Los datos
En esta actividad vamos a utilizar un juego de datos de diatomeas de los ríos franceses que se utilizó para varios proyectos, incluído mi tesis de doctorado (Tison et al. 2005; Bottin et al. 2014).
El juego de datos está en la carpeta de los datos en un archivo “diatomeas.RData”. Se carga así:
[1] "sp_abund_mat" "reference_sites" "env_info"
[4] "coord_x_y" Pueden ver que el archivo tiene variós elementos:
- sp_abund_mat es la matriz de abundancia de las especies de diatomeas en los sitios
- reference_sites es un vector logico que indica para cada sitio si es un sitio de referencia (en terminos de calidad del agua)
- env_info es un data.frame que contiene las variables de caracterisación ambiental de los sitios muestreados
- coord_x_y contiene las coordenadas de los sitios
El juego de datos está organizado de una manera que permite hacer vinculos directos entre las tablas: todas los objetos se corresponden elemento por elemento.
Anotar: esa organización de los datos es una mala practica. Es mucho mejor utilizar nombres de sitios y referencias explicitas a esos nombres en cada una de las tablas, pero nos sirve para este primer ejercicio!
nrow(sp_abund_mat)[1] 836length(reference_sites)[1] 836nrow(env_info)[1] 836nrow(coord_x_y)[1] 836Dentro de las variables de caracterización ambiental, existen variables que nos interesan para el ejercicio.
La variable HER1Lyon permite separar las hydro-eco-regiones:
barplot(table(env_info$HER1Lyon),cex.names=.65,xlab="Hydro-Eco-Región de nivel 1",ylab="Número de muestreos")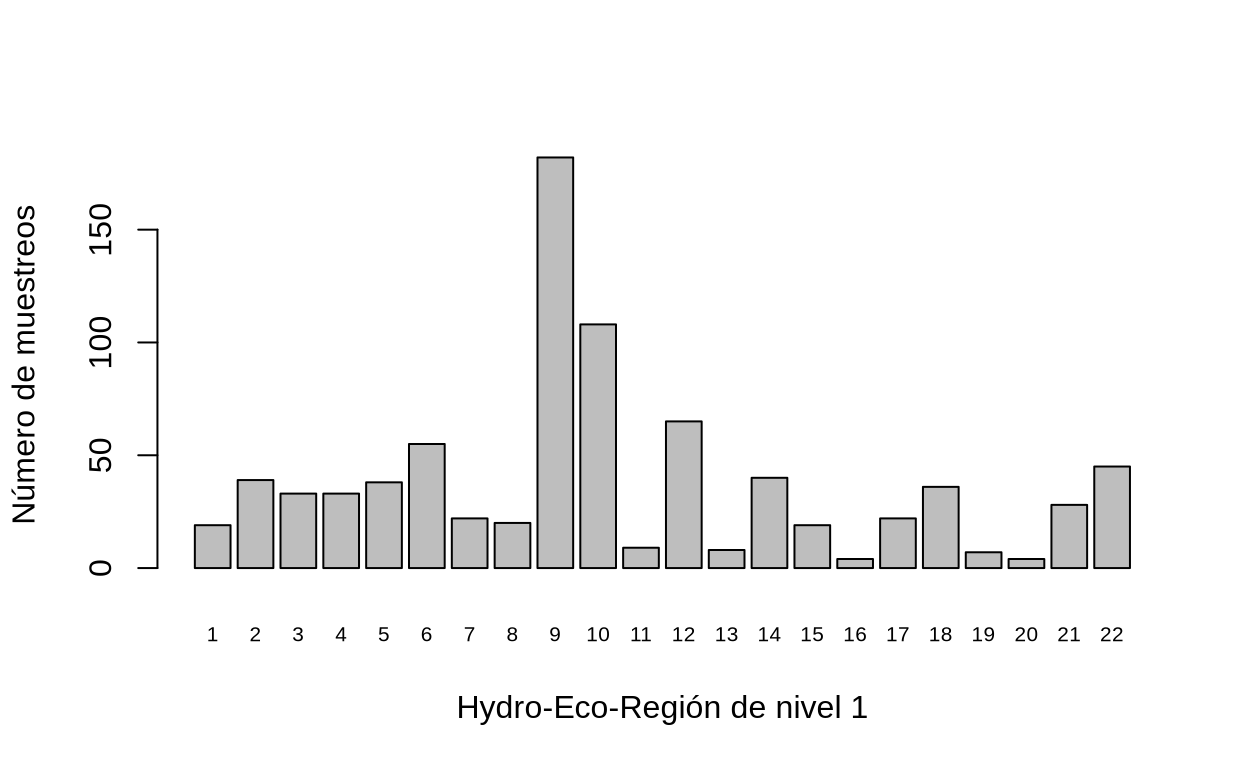
La variable PH nos da el valor de potencial \(H^+\) (los valores más pequeños son las aguas más acidas, los valores más altos son las aguas más alcalinas).
hist(env_info$PH,main="",xlab="pH")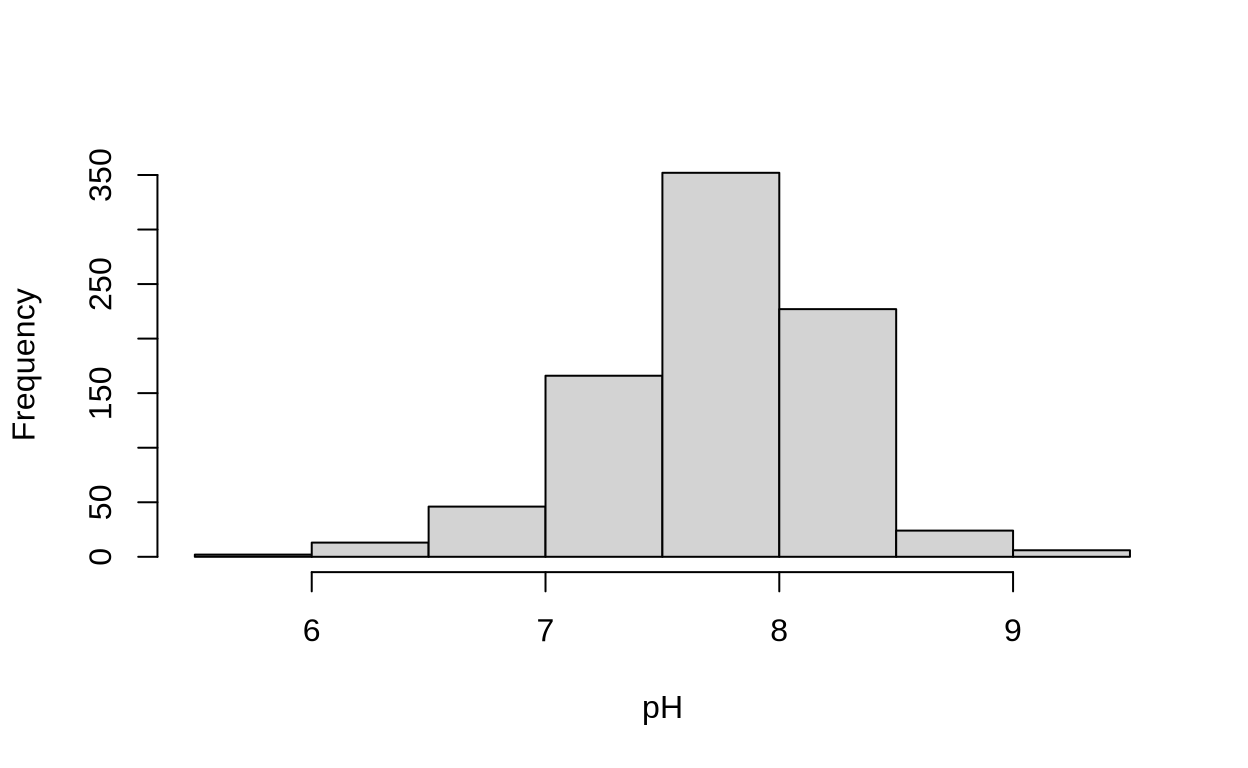
1.3 Indicaciones para el ejercicio
Para poder hacer este ejercicio, consultar la documentación sobre:
Además, puede ser útil mirar las ayudas de las funciones siguientes:
matrixpara crear una matrizComparisonpara las pruebas booleanas==,!=,>,>=,<Logicpara los operadores logicos&y|as.logicalymodepara cambiar el modo de variables numericas a logicascolSumsyrowSumspara calcular las sumas de las filas y columnas de un arrayquantilepara calcular los cuantiles de valor de un vector
2 Relaciones entre tablas en R
2.1 Ejercicio
La base de datos de diatomeas descrita en el primer ejercicio referencia los taxones por sus códigos, que están definidos por varios expertos europeos, pero esos códigos no son siempre especies, pueden corresponder a varios niveles taxonómicos.
Imaginemos que un grupo de investigadores quiere desarrollar un indice simple de calidad del agua como un cociente entre la abundancia de la familia Fragilariaceae y la familia Naviculaceae.
- Calcular ese indice para cada una de las muestras de la matriz sp_abund_mat
- Comparar los valores entre los sitios de referencia y los demás
Ejercicio suplementario para utilizar el mismo tipo de razonamiento (solo para si tenemos tiempo):
¡Hacer una matriz por nivel taxonomico!
2.2 Los datos
El archivo “diatomTaxonomy.RData” contiene 2 objetos:
- taxonomy que contiene informaciones sobre los taxones
- synonyms que contiene las sinonimías entre taxones (la taxonomía de las diatomeas es muy… dinámica!)
La tabla que nos interesa es el data.frame “taxonomy”:
str(taxonomy)'data.frame': 16739 obs. of 17 variables:
$ cd : chr "AAAP" "AAAR" "AABE" "AABL" ...
$ division : chr "Bacillariophyta" "Bacillariophyta" "Bacillariophyta" "Bacillariophyta" ...
$ subdivision : chr "Bacillariophytina" "Bacillariophytina" "Bacillariophytina" "Bacillariophytina" ...
$ class : chr "Bacillariophyceae" "Bacillariophyceae" "Bacillariophyceae" "Bacillariophyceae" ...
$ order : chr "Achnanthales" "Thalassiophysales" "Achnanthales" "Thalassiophysales" ...
$ suborder : chr NA NA NA NA ...
$ family : chr "Achnanthaceae" "Catenulaceae" "Achnanthaceae" "Catenulaceae" ...
$ genus : chr "Achnanthes" "Amphora" "Achnanthes" "Amphora" ...
$ species : chr "Achnanthes aapajaervensis" "Amphora acuta" "Achnanthes abundans" "Amphora abludens" ...
$ subspecies : chr NA NA NA NA ...
$ group : chr NA NA NA NA ...
$ variety : chr NA "var. arcuata" "var. elliptica" NA ...
$ form : chr NA NA NA NA ...
$ sp. : logi FALSE FALSE FALSE FALSE FALSE FALSE ...
$ authors_notes: chr "Cleve Euler " "var. arcuata (Schmidt in Schmidt & al.) Cleve " "var. elliptica Manguin in Bourrelly & Manguin " "Simonsen " ...
$ Family_Coste : chr "MO" NA "MO" NA ...
$ genus_cd : chr "ACHN" "AMPH" "ACHN" "AMPH" ...Como pueden ver la primera columna contiene los códigos que tenemos como nombres de columna de la matriz sp_abund_mat
2.3 Indicaciones para el ejercicio
Este documento muestra como funcionan las funciones which y match que son útil para este ejercicio.
Este documento tiene información sobre bucles.
3 Leer un archivo complejo
3.1 Ejercicio
Pasar los datos contenidos en el archivo “fitosociologiaFagusFrancia.xlsx” en:
- Una matriz de cobertura sitio x especie y la cobertura en porcentaje en la matriz
- Un data frame de información sobre los sitios
No modifiquen el archivo excel, todo se puede hacer en R, es por enfrentarse a este tipo de dificultades que nos mejoremos en R.
3.2 Los datos
Para su tesis de doctorado en la universidad de Burdeos sobre las comunidades de los bosques de hayas y sus distribuciones en la región de Burdeos, Marion Walbott (2018) ha utilizado varios datos fitosociológicos antiguos. En el archivo, pueden ver la transcripción de las tablas fitosociologicas de Lapraz (1963).
Esa tablas utilizan una escala de Braun-Blanquet:
bbScale <-data.frame(
code=c("r","+",as.character(1:5)),
description= c("Menos del 1% de cobertura, 3-5 individuos", "Menos del 5% de cobertura, pocos individuos","~5% más individuos","5%-25%","25%-50%","50%-75%","75%-100%"),
minPercent=c(0,1,5,5,25,50,75),
maxPercent=c(1,5,5,25,50,75,100)
)
bbScale$finalVal <- (bbScale$minPercent+bbScale$maxPercent)/2| code | description | minPercent | maxPercent | finalVal |
|---|---|---|---|---|
| r | Menos del 1% de cobertura, 3-5 individuos | 0 | 1 | 0.5 |
|
|
Menos del 5% de cobertura, pocos individuos | 1 | 5 | 3.0 |
| 1 | ~5% más individuos | 5 | 5 | 5.0 |
| 2 | 5%-25% | 5 | 25 | 15.0 |
| 3 | 25%-50% | 25 | 50 | 37.5 |
| 4 | 50%-75% | 50 | 75 | 62.5 |
| 5 | 75%-100% | 75 | 100 | 87.5 |
3.3 Indicaciones para el ejercicio
Para poder hacer este ejercicio, consultar la documentación sobre:
Además, puede ser útil mirar las ayudas de las funciones siguientes:
openxlsx::read.xlsxes una de las funciones para leer datos en archivos excel, no dudar en buscar los argumentos que les pueden facilitar el ejerciciois.napermite saber cuales son los valores que faltan en un vector, da un vector logicomatrixpara crear una matrizcbindyrbindpermiten concatenar arrays por filas o columnaspastepermite pegar varias cadenas de caracter juntasComparisonpara las pruebas booleanas==,!=,>,>=,<Logicpara los operadores logicos&y|as.logicalymodepara cambiar el modo de variables numericas a logicas
4 Construir funciones
En una base de datos, utilizamos este tipo de tablas para almacenar las abundancias o presencias de especies:
| Unidad de muestreo | Especie | abundancia |
|---|---|---|
| Bogotá | Canis lupus | 3000 |
| Bogotá | Felis catus | 1000 |
| Chingaza | Tremarctos ornatus | 50 |
| Chingaza | Canis lupus | 100 |
| Chingaza | Odocoileus virginianus | 200 |
Cuando vayamos a explorar las bases de datos estructuradas, les explicaré el porque de esa forma!
Desafortunadamente, los programas de análisis estadísticos funcionan mejor con este formato:
| Canis lupus | Felis catus | Tremarctos ornatus | Odocoileus virginianus | |
|---|---|---|---|---|
| Bogotá | 3000 | 1000 | 0 | 0 |
| Chingaza | 100 | 0 | 50 | 200 |
Nota, esas tablas se pueden crear en R para probar las funciones:
df_bog_chinga <- data.frame(
UniMuestreo=c(rep("Bogotá",2),rep("Chingaza",3)),
Especie=c("Canis lupus","Felis catus","Tremarctos ornatus","Canis lupus","Odocoileus virginianus"),
abundancia=c(3000,1000,50,100,200)
)
mat_bog_chinga <- matrix(c(3000,100,1000,0,0,50,0,200),nrow=2,dimnames=list(c("Bogotá","Chingaza"),c("Canis lupus","Felis catus","Tramarctos ornatus","Odocoileus viginianus")))4.1 Ejercicio
Contruir las funciones en R que permiten pasar de un formato “base de datos” a una matriz de abundancia o de presencia.
Las funciones deben tener los argumentos adecuados para :
- poder dar el nombre de la columna que contiene los taxones y de las unidades de muestreo
- poder manejar casos de presencia/ausencia, abundancia
- poder llenar las matrices con 0 o NA
- añadir todas las opciones que les parecen útil (un ejercicio más tarde consistira en publicar esas funciones en la forma de un paquete R en GitHub)
Construir una función que permita utilizar el formato “base de datos” y hacer la suma de todos las filas que tienen el mismo taxon en la misma unidad de muestreo, y utilizarla para construir la matriz de genero de diatomeas (ver ejercicio previo).
4.2 Indicaciones para el ejercicio
Puede ser util mirar la documentación sobre: